

Intro
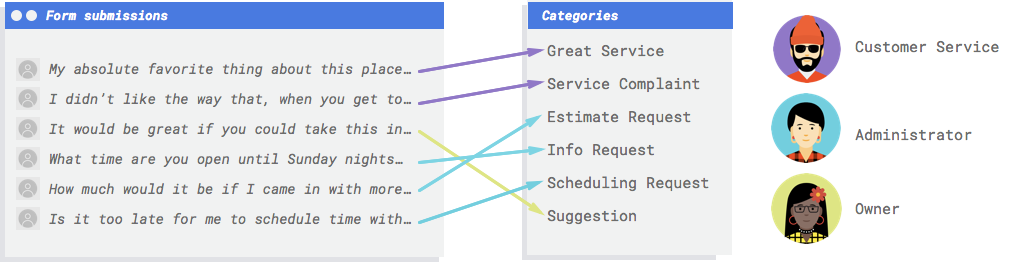
If you want to improve your customer service and streamline your workflow, you need a system that can automatically categorize the messages you receive from your website’s contact form. Such a system would analyze the content and tone of each message and assign it to one of five categories: complaints, praise, inquiries, appointments, or relationship-building. This way, you can easily prioritize the most urgent and relevant messages and forward them to the appropriate staff member. A system like this would save you time, increase customer satisfaction, and boost your business performance.In this post we will cover the essentials to put a step into Google AutoML.
What makes Machine Learning (ML) the appropriate solution for this issue?
Classical programming involves giving the computer step-by-step instructions to follow, but it becomes impractical when dealing with customer comments that use diverse vocabulary and structure. Building manual filters would not be effective in categorizing the majority of comments. To handle this problem, a system that can generalize to a range of comments is required. Machine learning systems are ideal for this task as they can learn from examples and adapt to changing data.
Should I use Cloud Natural Language API or AutoML Natural Language for my task?
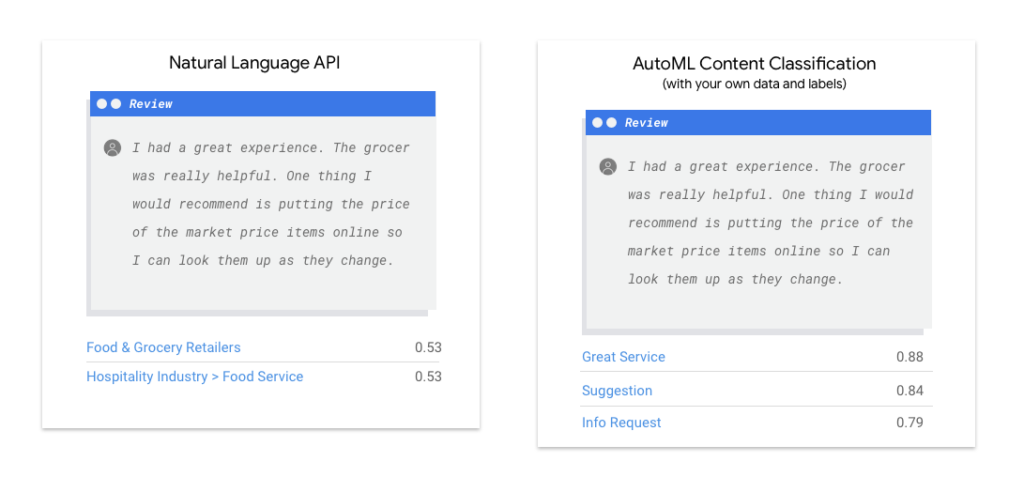
The Natural Language API is a tool that can help you analyze text. It can help you identify the structure of sentences, recognize different people, places, and things mentioned in the text, and even determine the overall mood or feeling conveyed by the words. If you have a lot of text that you want to sort into different categories (like news articles, for example), or if you just want to get a general sense of how positive or negative the text is, the Natural Language API could be a useful tool for you. However, if your text doesn’t fit neatly into the categories offered by the Natural Language API, or if you have your own specific labels that you want to use, you might need to experiment with other tools to find one that works better for your needs.
What is AutoML Natural Language’s machine learning process?
Machine learning is the process of using data to train algorithms to achieve a desired outcome. There are various subcategories within machine learning, each with its own unique problem-solving approaches and constraints. One such subcategory is AutoML Natural Language, which allows for supervised learning. In supervised learning, a computer is trained to recognize patterns from labeled data. This means that you can train a custom model to identify specific content within the text that is important to you.
Preparation of data
With Google AutoML Natural Language, you can easily create a custom model by providing labeled examples of the text items you want to classify and the corresponding categories or labels for the ML system to predict.
Evaluate your use case
To build a dataset, first, consider your use case. Ask yourself:
- What is the desired outcome?
- What categories need to be recognized to achieve this outcome?
- Can humans recognize these categories? Google AutoML Natural Language can handle more categories than humans, but if a category is unfamiliar to humans, it will be difficult for the system as well.
- What examples will accurately represent the data your system will classify?
Google’s ML products are based on human-centered machine learning, which emphasizes responsible AI practices such as fairness. The aim of fairness in ML is to avoid unjust or prejudiced treatment of people based on characteristics like race, income, sexual orientation, religion, gender, and other factors that have a history of discrimination and marginalization. This is important when algorithmic systems or algorithmically aided decision-making are involved.
Obtain your data source
To get the necessary data, first, determine what you require and then search for it. Start by reviewing the data your company currently collects. You may already have the necessary data to train a model. If not, you may obtain the data manually or by outsourcing it to a third-party provider.
Ensure adequate labeled examples for every category
Google AutoML Natural Language requires a minimum of 10 text examples per category/label for training. The more high-quality examples per label you have, the better your model’s accuracy. The number of samples needed depends on the consistency of the data you want to predict and your desired level of accuracy. For consistent data sets or 80% accuracy, fewer examples may be used. To achieve higher accuracy, you may need to train with 50 or more examples per label and continue to add more until your accuracy targets are met, which may require hundreds or even thousands of examples per label.
Equally distribute examples among categories
To ensure accurate model training, it’s important to have a balanced number of training examples for each category. Even if one category has more data, it’s best to distribute it equally among all categories. For instance, if 80% of the customer comments you use to train the model are estimate requests, the model may learn to predict that label more often than others. This can be compared to a multiple-choice test where most correct answers are “C” – the test-taker may start answering “C” without even reading the question.

When gathering examples for different labels, it is not always feasible to get an equal number for each group. Some categories may have fewer high-quality, unbiased examples available. In such situations, the label with the smallest number of examples should have at least 10% of the examples as the label with the highest number. For instance, if the biggest label has 10,000 examples, then the smallest label should have no less than 1,000 examples.
Record the variations in your problem space
To ensure that your machine learning model can handle new data, it’s important to provide a diverse set of examples in your training data. For instance, if you’re categorizing articles about consumer electronics, including multiple brand names and technical specifications can improve the model’s ability to identify the topic of an article, even if it’s about a brand that wasn’t in the training set. It may also be helpful to include a label for documents that don’t fit any of the defined categories. By doing so, you’ll enhance the model’s accuracy and improve its overall performance.

Make sure the data matches the desired output for your model
To improve your model’s performance, use text examples that are similar to what you want to predict. For instance, if you want to classify social media posts about glassblowing, using information from glassblowing websites may not be effective due to differences in vocabulary and style. It’s best to use real-world data from the same dataset you plan to classify.
Think about how AutoML Natural Language uses your data to create a custom model
Google AutoML Natural Language uses 80% of your data for training, 10% for validation, and 10% for testing by default.
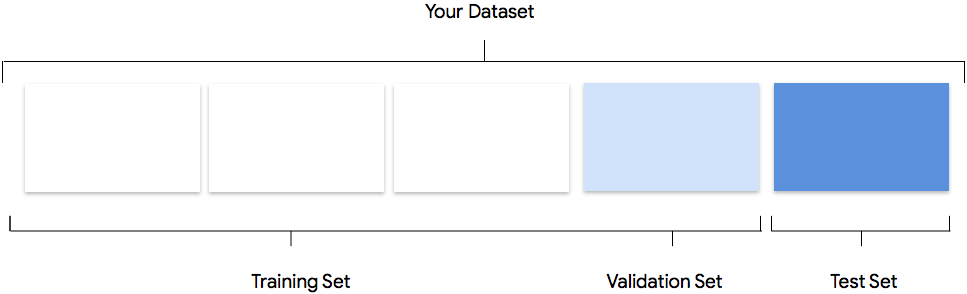

Training Set: Most of your data should be in the training set. This is what the model uses to learn and adjust its parameters, specifically the weights of the neural network connections.

Validation Set: The validation set, also known as the “dev” set, is used to fine-tune the model’s hyperparameters during the training process. This helps the model perform better on new data. If the hyperparameters were tuned using only the training set, the model may not generalize well to new examples. Using a different dataset for fine-tuning improves the model’s ability to generalize.

Test Set: The test set is not used during training. It’s used after training to evaluate the model’s performance on new data. This helps you understand how well the model will perform in the real world.

Manual Splitting: You can split your dataset manually if you want more control over the process or if you have specific examples that you want to include in a certain part of the model training.
Prepare your data for import
There are three ways to add data in Google AutoML Natural Language:
- Import data with labels sorted and stored in folders.
- Import data in CSV format with labels inline. This option is required if you want to split your dataset manually.
- Upload unlabeled text examples and use the Google AutoML Natural Language UI to apply labels.
Evaluate
Once the model is trained, you get a summary of its performance.
What should I consider before evaluating my model?
Debugging a model often involves debugging the data rather than the model itself. If the model behaves unexpectedly during evaluation or after deployment, it’s important to check the data for areas of improvement.
What analysis can I do in AutoML Natural Language?
In the AutoML Natural Language “Evaluate” section, you can evaluate your custom model’s performance using its output on test examples and machine learning metrics. This section explains the following concepts:
- Model output
- Score Threshold
- True positives, true negatives, false positives, and false negatives
- Precision and recall
- Precision/Recall Curves
- Average precision
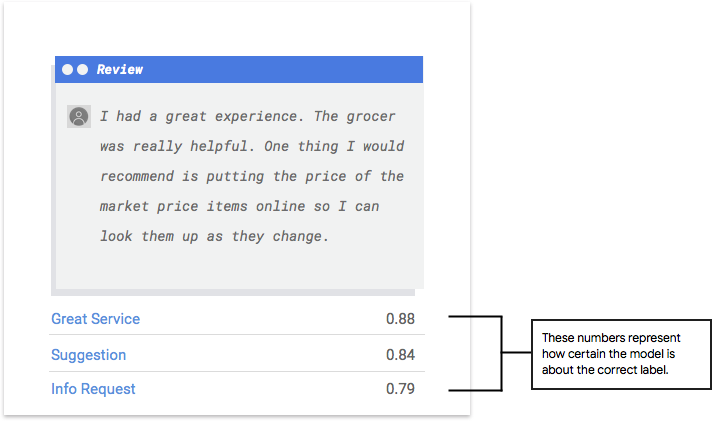
How to interpret the model’s output?
AutoML Natural Language presents new challenges to your model by using examples from your test data. For each example, the model outputs a series of numbers that indicate how strongly it associates each label with that example. A high number means the model is confident that the label should be applied to that document.
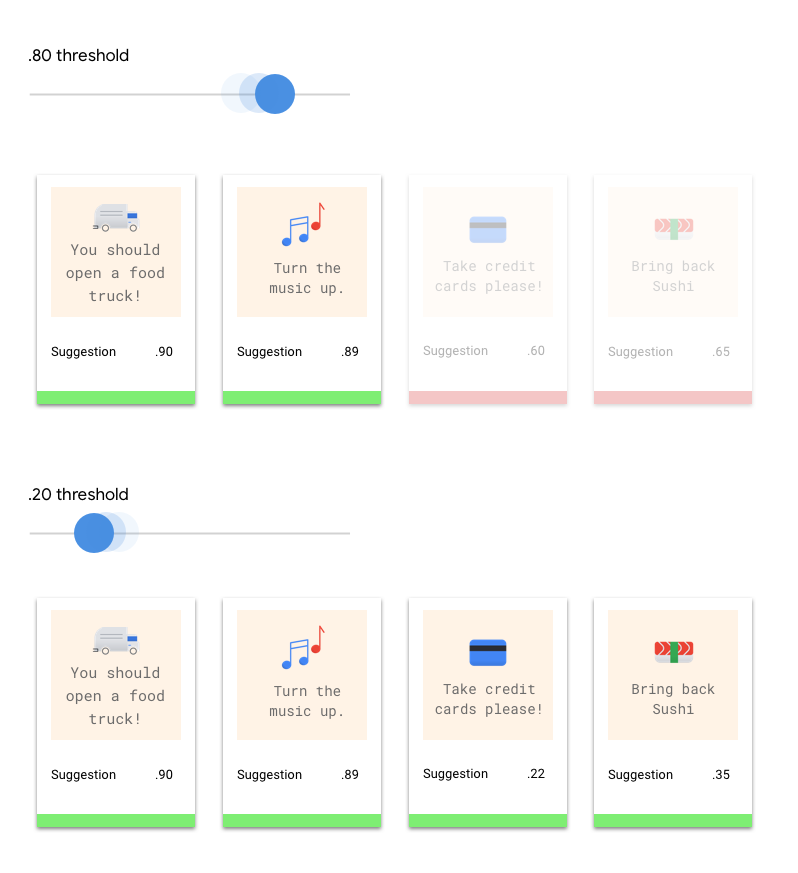
What does Score Threshold mean?
The score threshold in AutoML Natural Language converts probabilities into binary values. It determines the level of confidence the model needs to assign a category to a test item. The score threshold slider in the UI allows you to test different thresholds visually. If the threshold is set high, the model will classify fewer text items but with a lower risk of misclassification. If the threshold is set low, the model will classify more text items but with a higher risk of misclassification. You can experiment with per-category thresholds in the UI, but you’ll need to enforce optimal thresholds when using the model in production.
Explaining True Positives, True Negatives, False Positives, False Negatives
After applying the score threshold, the model’s predictions will fall into one of four categories.
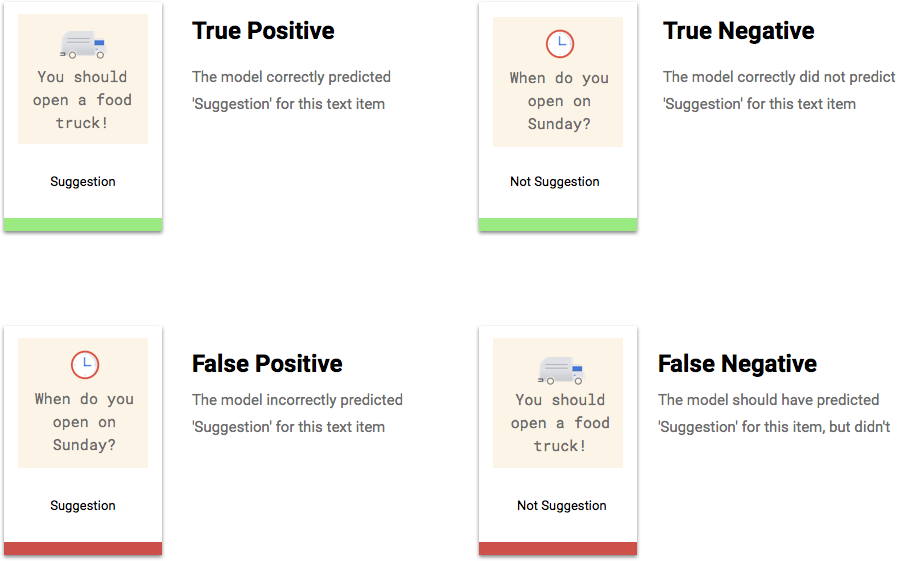
These categories can be used to calculate precision and recall, which are metrics that measure the effectiveness of your model.
Identifying precision and recall?
Precision and recall measure how well the model captures information and how much it misses. Precision indicates how many test examples assigned to a label were actually supposed to be categorized with that label. Recall indicates how many test examples that should have had the label assigned were actually labeled.
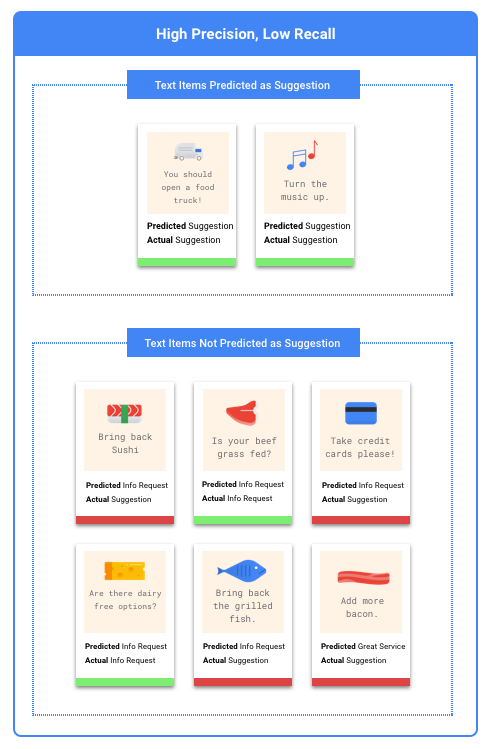
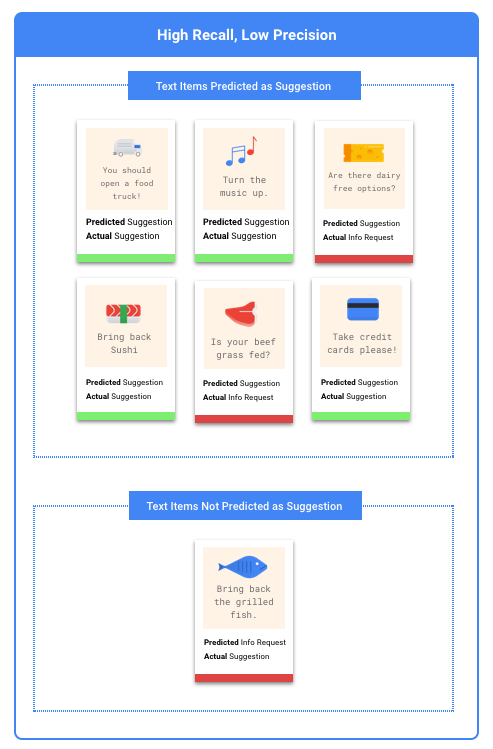
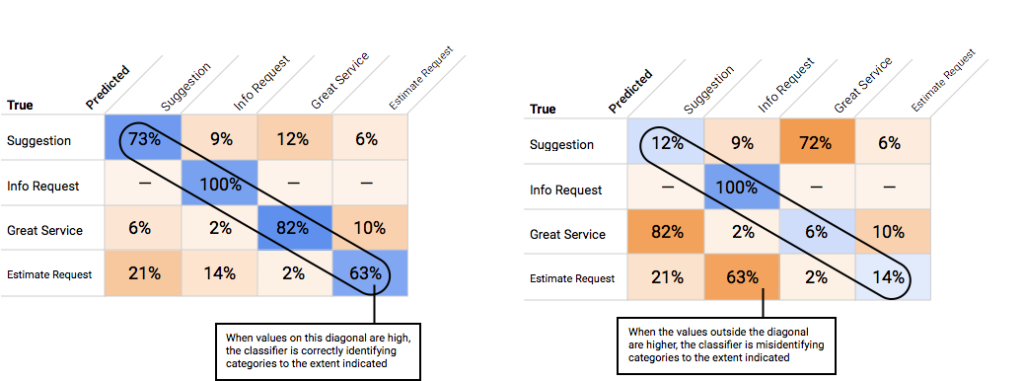
How to use the Confusion Matrix?
We can use a confusion matrix to compare the model’s performance on each label. In an ideal model, the diagonal values will be high and the other values will be low, indicating correct identification of categories. High values in other areas of the matrix indicate how the model is misclassifying test items.
What is Average Precision?
The area under the precision-recall curve is a useful metric for model accuracy. It measures the model’s performance across all score thresholds and is called Average Precision in AutoML Natural Language. A score closer to 1.0 indicates better performance on the test set, while a model guessing at random for each label would get an average precision of around 0.5.
Test your Model
AutoML Natural Language automatically uses 10% of your data for testing, and the “Evaluate” page shows how the model performed on that data. However, if you want to double-check the model, you can input text examples into the “Predict” page and see the labels the model assigns. This is an easy way to ensure the model matches your expectations. Try a few examples of each type of comment you expect to receive.
0 Comments