

Recently, researchers from the Australian National Academy, Oxford and KLCII proposed an agent framework driven by LLM to generate complex 3D scenes with text prompts. Are the omnipotent models really going to start creating 3D worlds?
Following the popular AI Wensheng picture and Wensheng video on the whole network, the technology of the Wensheng 3D scene is also here!
With less than 30 words of prompts, such a 3D scene can be generated in an instant.
The effect of the scene and the requirements of the text are almost the same -“The lake, serene and glassy, mirrored the cloudless sky above, reflecting the surrounding mountains and the graceful flight of a heron, as lily pads floated like emerald jewels upon its tranquil surface.”
“The desert, an endless sea of shifting sands, stretched to the horizon, its rippling dunes catching the golden rays of the setting sun, creating an ever-changing landscape of shadows and light.”
The research team planned to publish the project’s code on Github as soon as the paper was accepted, but before the code was published, the project had already received 210 stars!
Unlike the independent models that the Wensheng graph relies on, 3D-GPT still uses the multimodal and inference capabilities of large language models (LLM) to decompose 3D modeling tasks into multiple subtasks, which are completed by different agents, including task scheduling agents, conceptual agents, and modeling agents.
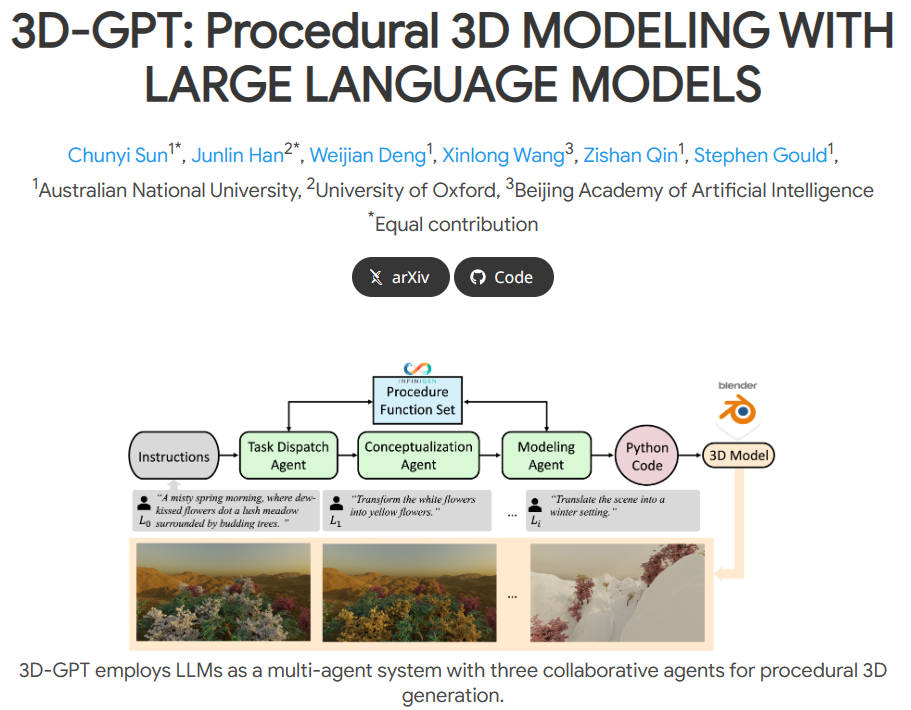
According to the researchers, 3D-GPT positions LLM as a skilled problem solver, breaking down procedural 3D modeling tasks into accessible parts and assigning appropriate agents to each task.

The whole system does not require any training, and the process from text to parameter extraction to 3D modeling can be completed without training.
Specifically, the task scheduling agent is responsible for selecting the appropriate program-generated function based on instructions. Conceptualization agents reason about textual descriptions, filling in missing details.

The modeling agent infers function parameters, generates Python code, and controls the 3D modeling software Blender through the API to model it.

The system integrates seamlessly with Blender and supports object deformation, material adjustment, mesh editing, physics simulation, and more.
The 3D GPT framework can enhance the short scene description provided by the user, making it more detailed and contextual. At the same time, the program generation method is integrated to extract parameters from rich text to control the 3D modeling software.
And because LLM can provide excellent semantic understanding and contextual capabilities, 3D GPT can generate a variety of 3D assets and supports continuous, targeted editing and modification capabilities.

3D-GPT enables fine object control, including the capture of shapes, curves, and details, resulting in detailed modeling. At the same time, you can also control the generation of large scenes.

Moreover, 3D GPT supports continuous instruction input, which can edit and modify the scene. The system remembers previous changes, connects new instructions to the scene context, and allows users to continuously edit and modify the generated scene.

In addition, 3D-GPT also supports continuous editing of individual elements and functions through natural language, such as the figure below, which shows that users can modify weather effects individually by changing input requirements.

Task definition
The overall goal is to generate 3D content based on a series of natural language instructions.
Among them, the initial instruction L0 acts as a comprehensive description of the 3D scene, such as “a foggy spring morning with dew-kissed flowers dotting a lush meadow surrounded by newly sprouted trees“.
Subsequent commands are used to modify existing scenes, such as “change white flowers to yellow flowers” or “convert the scene to winter environment“.
To accomplish this, the researchers introduced a framework called 3D-GPT, which enables large language models (LLMs) to act as problem-solving agents.
Model preparation
The researchers point out that getting LLM to directly create every element of 3D content presents significant challenges. LLMs may have difficulty with skilled 3D modeling due to the lack of specialized pre-training data, and as a result, they may struggle to determine exactly which elements should be modified based on a given instruction and how.
To deal with this problem, in the researchers’ framework, they utilized Infinigen, a Python-Blender-based process generator from previous research, which is equipped with a rich library of generative functions.
To make LLMs proficient with Infinigen, the researchers provided key hints for each function. These tips include function documentation, easy-to-understand code, required information, and usage examples.
By providing LLM with these resources, researchers enable them to develop their core competencies in planning, reasoning, and tool utilization. As a result, LLMs can effectively use Infinigen for language instruction-based 3D generation, a process that is seamless and efficient.
Multi-agent system for 3D inference, planning, and tool usage
Once the tool is ready, 3D-GPT employs a multi-agent system to handle procedural 3D modeling tasks.
The system consists of three core agents: a task scheduling agent, a conceptualization agent, and a modeling agent, as shown in Figure 1 below.
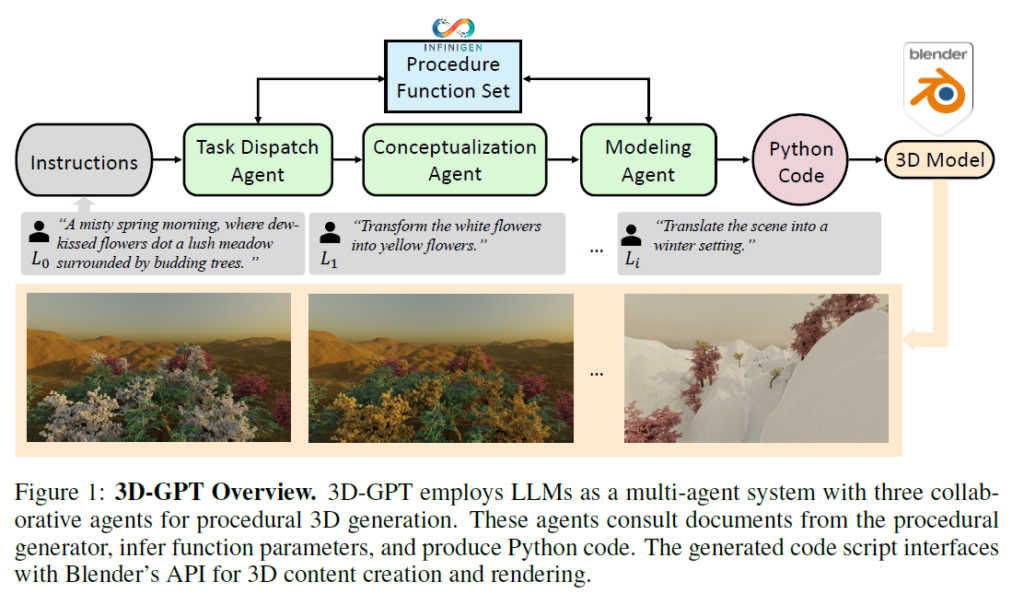
Together, they break down procedural 3D modeling tasks into manageable pieces, with each agent focusing on different aspects: 3D inference, planning, and tool usage.
Task scheduling agents play a key role in the planning process. It queries function documentation using user instructions and then selects the necessary functions for execution.
Once the function is selected, the conceptualization agent enriches the user-supplied textual description with inference.
On this basis, the modeling agent infers the parameters of each selected function and generates Python code scripts to call Blender’s API, thereby facilitating the creation of corresponding 3D content. In addition, you can use Blender’s rendering capabilities to generate images.
Task scheduling agents are used for planning
The task scheduling agent has comprehensive information about all available functions F and can efficiently identify the functions required for each instruction input. For example, when the instruction “Convert the scene to a winter environment” appears, it finds functions like add_snow_layer() and update_trees() precisely.
This critical role of the Task Scheduling Agent facilitates efficient task coordination between conceptualized and modeling agents.
Without it, conceptualization and modeling agents must analyze all provided functions for each given instruction, which not only increases the workload of these agents but also lengthens processing time and can lead to unexpected modifications.
The communication process between the LLM system, users, and task-scheduling agents is as follows:
Conceptualized agents are used for inference
The description may not explicitly provide a detailed description of what it looks like for modeling. For example, consider the description: “On a foggy spring morning, dew-kissed flowers dotted lush meadows surrounded by newly sprouted trees.” ”
When using tree modeling functions that require parameters such as branch length, tree size, and leaf type, it is clear that these specific details are not directly stated in the given text.
When instructing the modeling agent to infer parameters directly, it tends to provide simple solutions, such as using default or reasonable values from parameter documents, or copying values from prompt examples. This reduces the diversity of generation and complicates the process of parameter inference.
Modeling agents can use tools
After conceptualization, the goal of 3D modeling processing is to translate detailed human language into machine-understandable language.
Blender rendering
The modeling agent finally provides Python function calls with inference parameters that are used for Blender node control and rendering, resulting in the final 3D mesh and RGB results.
Build effect edits and modify experiments
The researchers’ experiment began by demonstrating the efficiency of 3D-GPT in consistently generating results corresponding to user instructions, covering a variety of scenarios involving large scenes and individual objects.
The researchers then delved into specific examples to illustrate how the researchers’ agents effectively understood the tool’s functionality, gained the necessary knowledge, and used it for precise control. To deepen the researchers’ understanding, the researchers conducted ablation studies that systematically examined the contribution of each agent in the researchers’ multi-agent system.
3D modeling
Large scene generation
The researchers investigated the ability of 3D-GPT to control modeling tools based on scene descriptions.
To conduct this experiment, the researchers used ChatGPT to generate 100 scene descriptions with the following prompt: “You are a good writer, please provide me with 10 different descriptions of natural scenes.”
The researchers collected 10 responses to this prompt to form their dataset. In Figure 2 below, the researchers show the results of a multi-view rendering of 3D-GPT.
The results show that the researchers’ method can generate large 3D scenes that roughly match the text descriptions provided, and demonstrate significant diversity.
It is worth noting that all 3D results are rendered directly using Blender, ensuring that all meshes are realistic, allowing the researchers’ approach to achieve absolute 3D consistency and produce realistic ray-traced rendering results.
Detail control in a single category
In addition to generating large scenes from concise descriptions, the researchers also evaluated 3D-GPT’s ability to model objects. The researchers evaluated key factors such as curve modeling, shape control, and a deep understanding of the appearance of objects.
To this end, the researchers presented the results of fine-grained object control. This includes subtle aspects derived from the input text description, such as object curves, key appearance features, and colors.
The researchers used random cues to guide GPT in generating a variety of real-world flower types. As shown in Figure 3 below, the researchers’ method expertly modeled each flower type, faithfully capturing their different appearances.
This study highlights the potential of 3D-GPT for accurate object modeling and fine-grained attribute control.
Subsequence instruction editing
The researchers tested 3D-GPT’s ability to communicate effectively with humans and agents and task manipulation.
In Figure 4 below, the researchers observed that the researchers’ method was able to understand subsequence instructions and make accurate scene modification decisions.
It is worth noting that, unlike existing text-to-3D methods, 3D-GPT preserves the memory of all previous modifications, thus helping to connect the new instructions with the context of the scene.
In addition, the researchers’ approach eliminates the need for additional networks for controlled editing. This study highlights the efficiency and versatility of 3D-GPT in proficiently processing complex subsequence instructions for 3D modeling.
Single function control
To assess the effectiveness of 3D-GPT in the use of the tool, the researchers presented an illustrative example that highlighted the ability of the researchers’ approach to control for single functions and infer parameters.
Figure 5 below illustrates 3D-GPT’s ability to model the appearance of the sky based on input text descriptions.

The functions responsible for generating the sky texture do not directly associate color information with the appearance of the sky. Instead, it relies on the Nishita sky modeling methodology, which requires a deep understanding of real-world sky and weather conditions and consideration of input parameters.
The researchers’ approach expertly extracts key information from text input and understands how each parameter affects the final appearance of the sky, as shown in Figures 5(c) and (d). These results show that the researchers’ approach can effectively use single functions as well as infer corresponding parameters.
0 Comments