

EagleX 1.7T – in short
EagleX 1.7T is an early research release of the 7.52B parameter model training that:
- Is part of a larger 2T model training
- Is built on the RWKV-v5 architecture
(a linear transformer with 10-100x+ lower inference cost) - Is continuation based on the original Eagle 7B model
- Ranks as the world’s greenest 7B model (per token)
- Trained on 1.7 Trillion tokens across 100+ languages
- Outperforms all 7B class models in multi-lingual benchmarks
- Passes LLaMA2 (2T) in multiple English evals, approaches Mistral (>2T?)
We are releasing RWKV-v5 EagleX 1.7T, licensed under Apache 2.0, which can be used personally or commercially without restrictions.
- Download from HuggingFace
- Try it online today on
- Use our reference pip inference package, or any other community inference options (Desktop App, RWKV.cpp, etc) , and use it anywhere (even locally)
- Fine-tune using our Infctx trainer
- [Pending PR] Get support merged into Huggingface transformers!
- All eval data can be found in the google sheet here
What does it mean to fly pass LLaMA 7B?
Claiming to have caught up with and surpassed the ‘Gold Standard’ of the 7B weight class from scratch is a substantial assertion, especially since nearly every other major open access model, including Mistral, is allegedly built upon it. This claim is even more significant considering it was achieved with a relatively smaller dataset token count of 1.7 trillion tokens compared to 2 trillion tokens.”
Going big on eval data
As this is a entirely different model, trained from scratch, there will be evals that we win and we lose, which we are fully transparent about, in showing how we are ahead of LLaMA 7B on average.
Instead of simply cherry picking 14 different evals which we won and calling it a day with a victory, we ran ALL the benchmarks in EleutherAI `lm-eval-harness`, at commit `f78e2da` that we could do, with the following limitations:
- It has to complete in under 30 minutes on 8×4090 (we were running lots of evals)
- This rules out some of the rather more expensive long chain of thought evals
- We excluded all the personality / alignment evals
- Eval has to be executable across a wide variety of models, via lm-eval-harness
- All evals are 0 shot (no 5 shot-ing an MCQ question)
- We limited comparison to other models within the 7B weight class
These resulted into running 60+ major eval groups, which generated over 1,000+ data points per model. A data point count so high, that we had to drop standard error deviations, just to ensure the raw CSV file can be loaded in MacOS numbers.

Whew, that’s a crazy number of data points to digest. Let me break it down to more digestible parts:
- English perplexity
- Multi-lingual performance
- 21 English Eval Focus
- 183 English Evals
All data shown here is made available in the Google Sheet over here:
We included explanations of what several of the evals mean, which you can keep in mind in future eval results you see (demystify what those numbers mean!)
Winning English Perplexity
We start with the basics: Perplexity. This is the loss value against the test dataset (lower score = better), i.e. how good the model is with next token prediction.
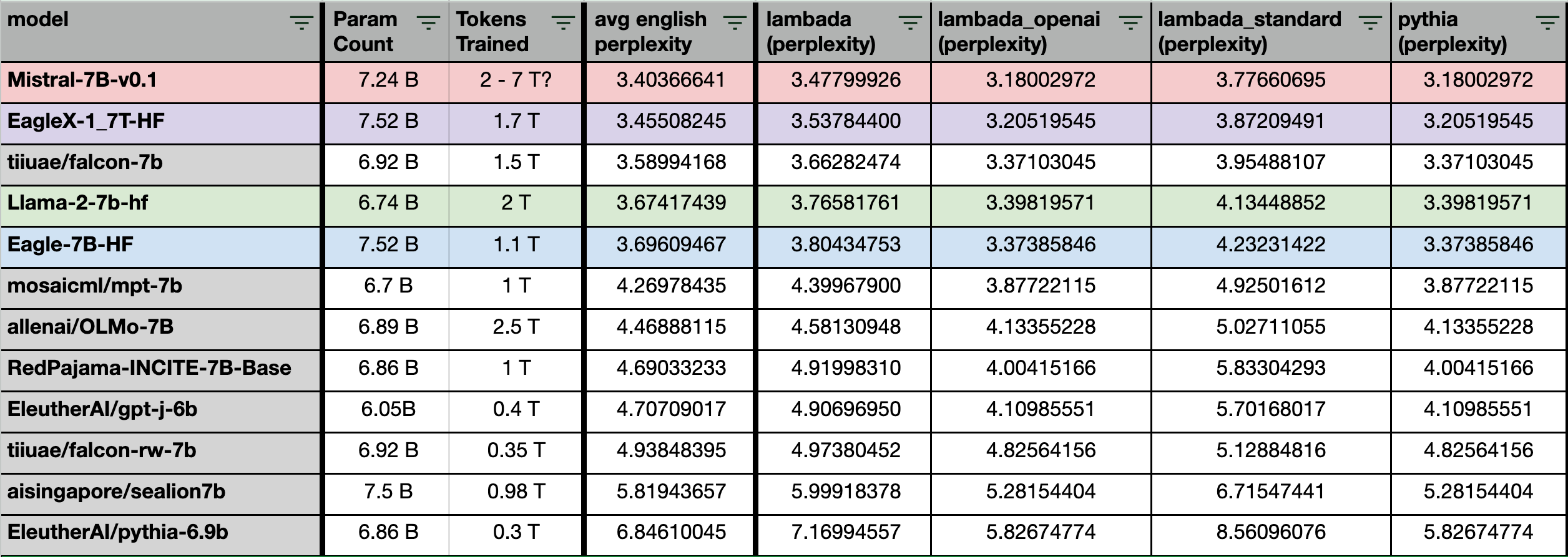
In general, with the perplexity improvements, the EagleX model outperforms LLaMA2-7b, ranking between Falcom/LLaMA2-7b and Mistral.
Why do experts care about perplexity?
Eval in general can be very subjective, and opinion driven, and commonly gives mixed results. Perplexity in a way gives the TLDR summary for most experts to start with
Leading Multi-lang Perplexity & evals
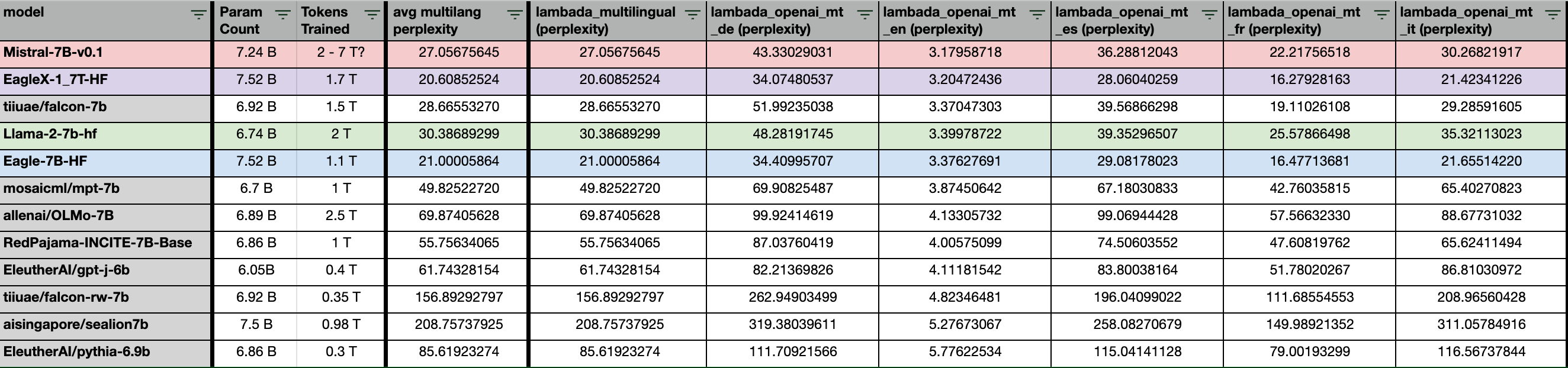
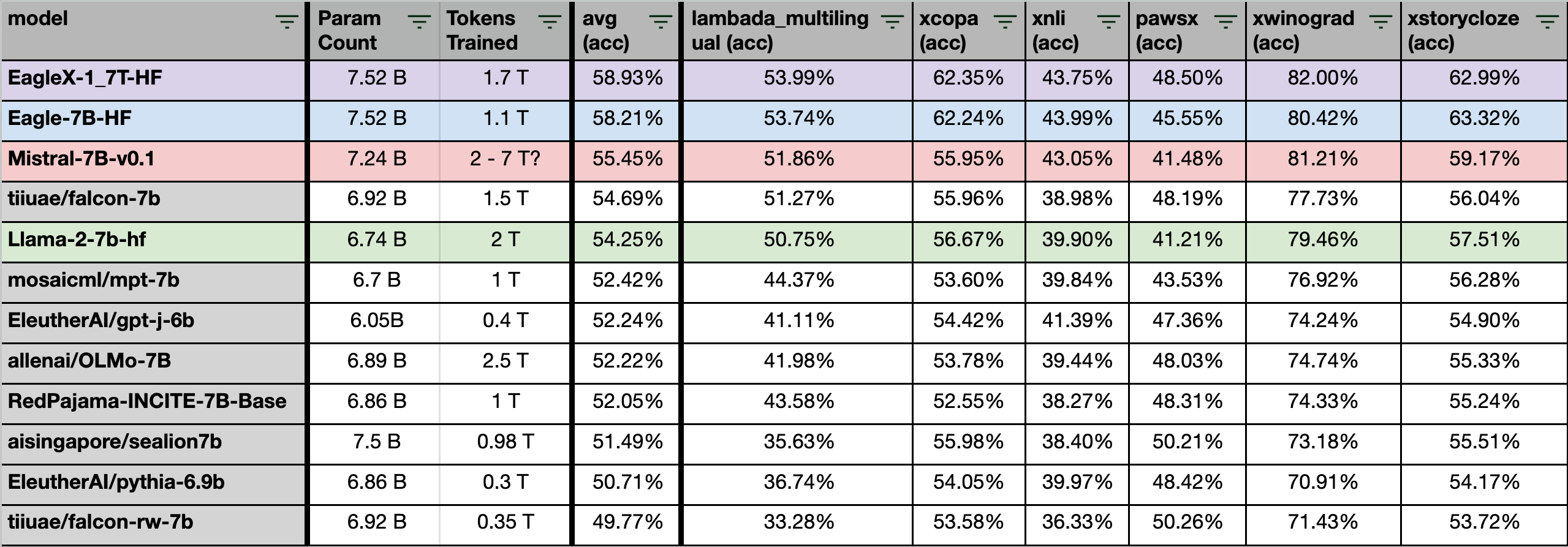
EagleX maintains the lead for best-in-class multi-lingual performance, with the incremental improvements we’re making to the Eagle line of models.
Most of the tasks here are common sense reasoning tests of a wide variety of formats, across languages including 23 of the world’s most widely used languages.
Why is multi-lingual perf important?
The objective of the RWKV project and the Eagle series of models is to develop inclusive AI that serves everyone, irrespective of their language. It aims to construct AI models that cater not only to English speakers but also to the 83% of the global population who use a non-English language daily.
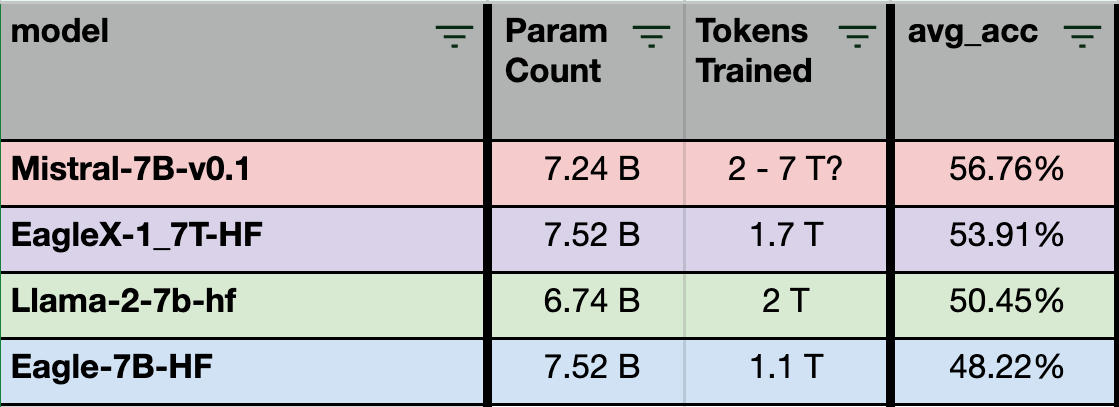
21 English Evals
Nevertheless, English is still important. We reduced the evals down to 21 of the argubly most popular English evals, such as Lambada, Glue, Swag, Winogrande, TruthfulQA, MMLU:

Focusing on the four models that are of primary interest – LLaMA, Mistral, EagleX, and Eagle-7b – the new EagleX model surpasses LLaMA-2-7b in performance on average across the 21 evaluations and is closely competitive with Mistral.”
The Good
Now, let’s look at where our model is blowing the rest of the models out of the water.
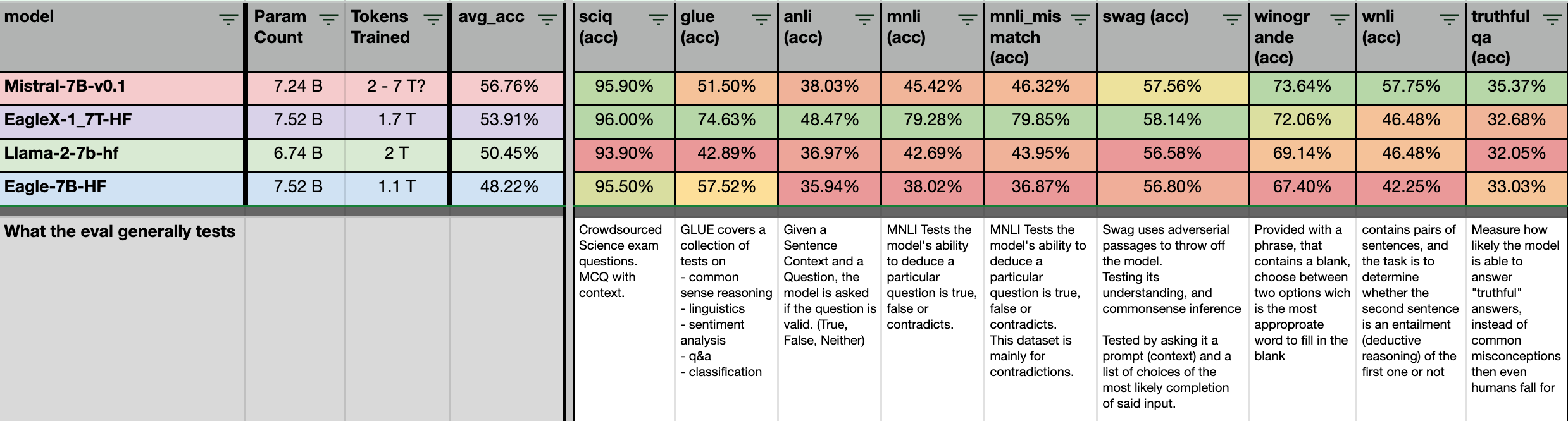
Initially, the most notable aspect is the performance of the first six evaluations, where our modestly-sized 1.7T trained model surpasses even the Mistral 2T++ trained model (including sciq, glue, anli, mmnli, swag) across various tasks. These tasks are centered around contextual Q&A that require common sense reasoning or deductive logic. Additionally, EagleX outperforms LLaMA-2-7b in wingrade and wnli evaluations, which also involve contextual common sense reasoning. This suggests that the EagleX model could be effectively utilized in RAG use cases, predominantly contextual Q&A, with appropriate prompt engineering.
In conclusion, regarding truthful, although it exceeds LLaMA’s performance, I believe this still highlights the susceptibility of all models to acquiring common human misconceptions from the web, as evidenced by the poor scores across all models.
(To be fair, this is also challenging for most humans.)
P.S: The significant improvement in glue/mnli was so substantial that we had to scrutinize the dataset for potential contamination. However, we were unable to find any evidence of it. This leap in performance is currently attributed to the use of multiple training datasets and a data-augmented/machine-rewritten instruct dataset that follows a similar structure.
Strong common sense reasoning over context has highly valuable applications in various RAG use cases.
The Mixed
Next: the eval sets with mixed results. Here, we have very similar evals with 2 major variants. The results between EagleX and LLaMA are close enough, that it’s hard to say which model is better between the two for these evals.
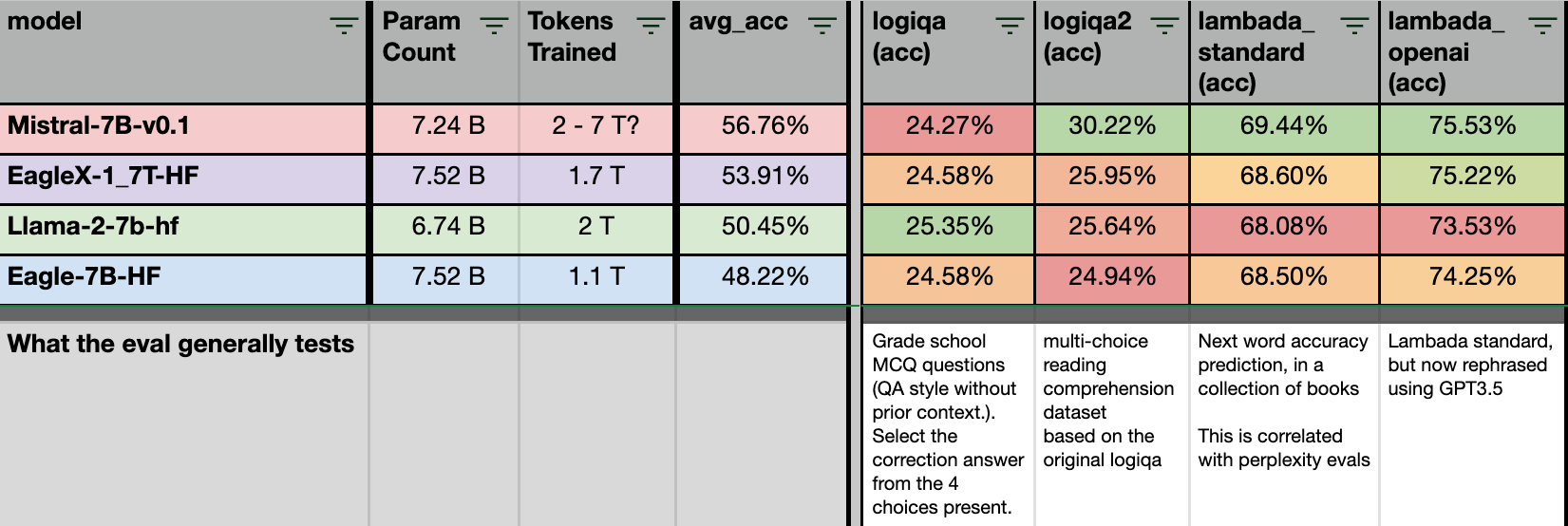
What’s interesting, is that even though logiqa can be seen as form of “common sense” reasoning test, the EagleX model scored much lower compared to the 6 evals (sciq, glue, anli, mmnli, swag). This could mean that while the model is better at reasoning given a context, but it lacks the depth of knowledge compared to other models with more token training.
The “Not too bad“ and the “Really Bad”
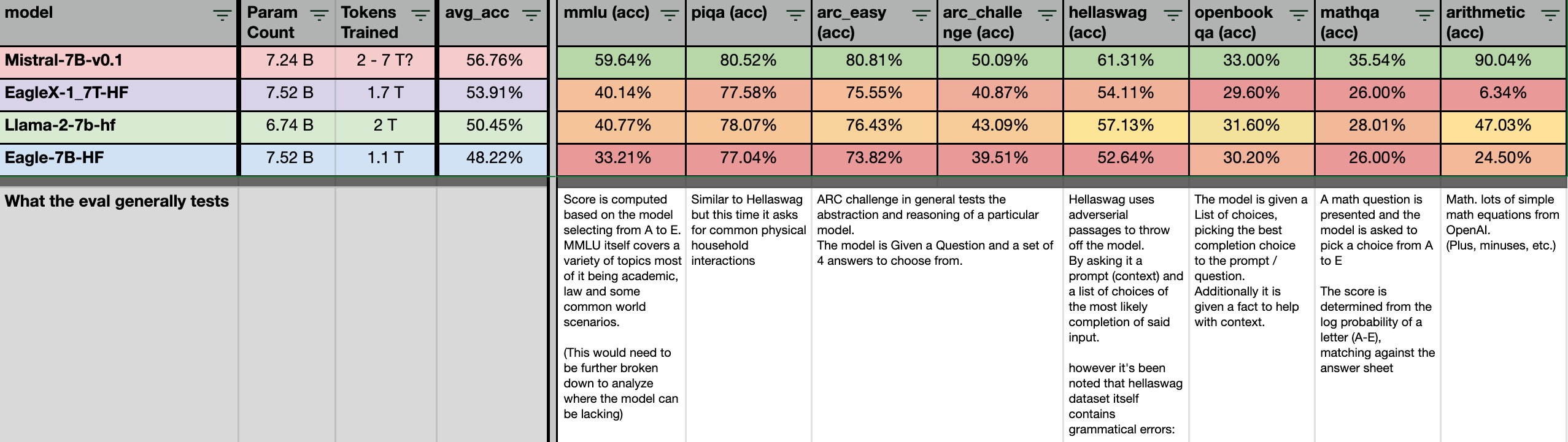
These are the evals the the EagleX performs worse on compared to both Mistral and LLaMA. However, for the evals that we’ve lost to LLaMA, it’s by a narrow margin. But we’ll be keeping track of these as we train past 2T tokens.
Let’s look what went really badly: Math.
The results for arithmetic eval sank drastically, like a rock, even compared to our original Eagle model.
What went wrong?
We dug through the dataset we used for training, and realized we missed out the entire math dataset (along with a few others) due to an error. Oops.
This emphasize the importance of maintaining the dataset composition over the training run. We’re adding math back for future runs.
We expect overall math score to rise back up as the training continue, however realistically IMO – no one should be depending on a 7B model for math (just saying)
183 English Evals
We do not simply want to cherry pick 9 or 21 evals and claim victory over LLaMA, or even Mistral. So, let’s zoom out, and look at it holistically across 183 English evals.
You can view the full results here
Although using the overall averages across all the evals does have a bias the results towards larger eval sets (due to double counting, e.g. mmlu overall and many indivudall mmlu test), it does not change the ranking among the EagleX, Mistral, LLaMA and the original Eagle models.
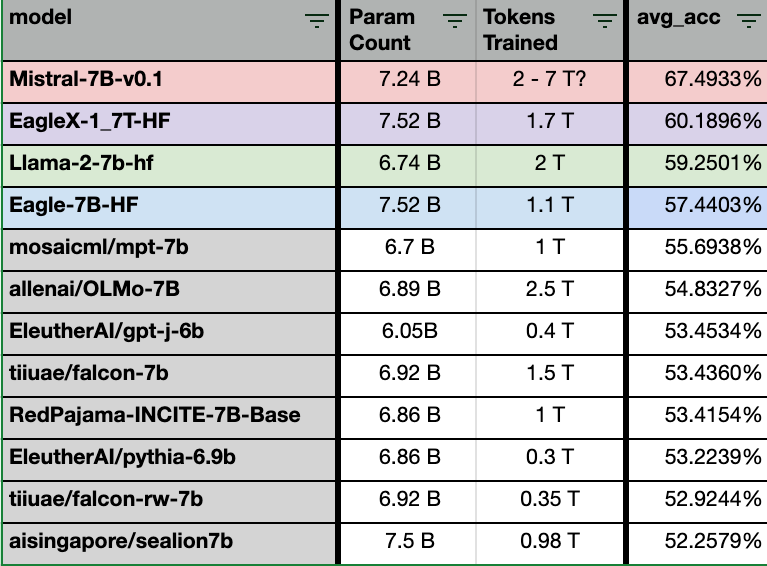
However these results is extremely useful for smaller insights, for example

The EagleX model was outperformed by LLaMA2 in the domain of US history, yet it triumphed in world history. This outcome aligns with the expansive methodology employed in creating the dataset, which was designed to be inclusive and globally oriented rather than US-centric.
The detailed insights will be used by our dataset team to iterate and improve on our future datasets.
How the model answer, is a reflection of the dataset experiences it has learned
How much resources the model consumes, is a reflection of its architecture
Perhaps a good dataset + Scalable architecture: is all you need?
One of the biggest changes made was to change the dataset for the current 1T tokens, which now uses a cleaner filtered set of data with careful considerations to ensure permissible licensed content sources used.
There are also huge implications for the fact, that the model crossed the llama2 line earlier than the plan schedule. Either the architecture is more efficient in training, or the improvements in dataset quality has a large impact on model performance.
The following is a summary of the dataset used, its public release will be made available next month after the current 2T training is completed.
## 15% Code
Contains code/programming related topics
- the-stack
- codeparrot
- devopedia
- mdn
## 15% Multi lang
Generally multi-lang webtext
- sea-lion (Singapore)
- madlad
- culturax
- multi lang wiki
## The giant soup
Creative content
- fandom (only sites with permissive licenses, and low spam)
- scp-foundation
Wikipedia
- Various Permissively licensed wikis.
- wikipedia
Papers:
- Mainly arxiv (Permissive Licenses) and pes2o
Books:
All the books contained in out train sets are public domains books.
- gutenberg,
- standardebooks
Webtext
- webtext
- refinedweb (Note: This chunk made the model worse, we recommend against refinedweb in future trains)
- slimpajama
- europarl
- eurlex.
- stackexchange
Various
- aya (multilang convo)
- some system prompt, instruct
- long list of sub 100B training datasets on HF
- rewritten text !!! (splicing in, to replicate the rewritten web paper)The Milestone
In overall, the release of this model marks an important milestone and transition for many of us, within both the commercial team within Recursal AI, and the open source team in the RWKV group.
- Its the first major training done by the Recursal AI team, in partnership with AWS as our main compute provider
- This model is being released under Apache 2 licensing
- The fully trained 2T model will be released under the RWKV group, under the Linux Foundation
- The first Non-Transformer Architecture to pass LLaMA2 in evals
- The strongest Linear Transformer to date
- Proof you can have both strong multi-lingual and english performance
What’s next?
Similar to the original Eagle 7B announcements, the following is the revised goals for the model training
- [April 2024] Completion of the 2T Eagle 7B models
- [March-May 2024] Training of our v6 “Finch”line of models
- [June 2024] v6 MoE model, for GPT 3.5 class performance
Disclaimer: All dates are approximate, and is heavily subjected to compute availability from our sponsors/compute-provider/investors
Want more?
If you want find more about the RWKV opensource Project at
- Wiki: https://wiki.rwkv.com/
- Discord: https://discord.gg/bDSBUMeFpc
Source: substack.recursal.ai
0 Comments