

LPU is a new type of processing system designed for inference performance and precision, especially for large language models (LLMs).
The advantages of the LPU Inference Engine
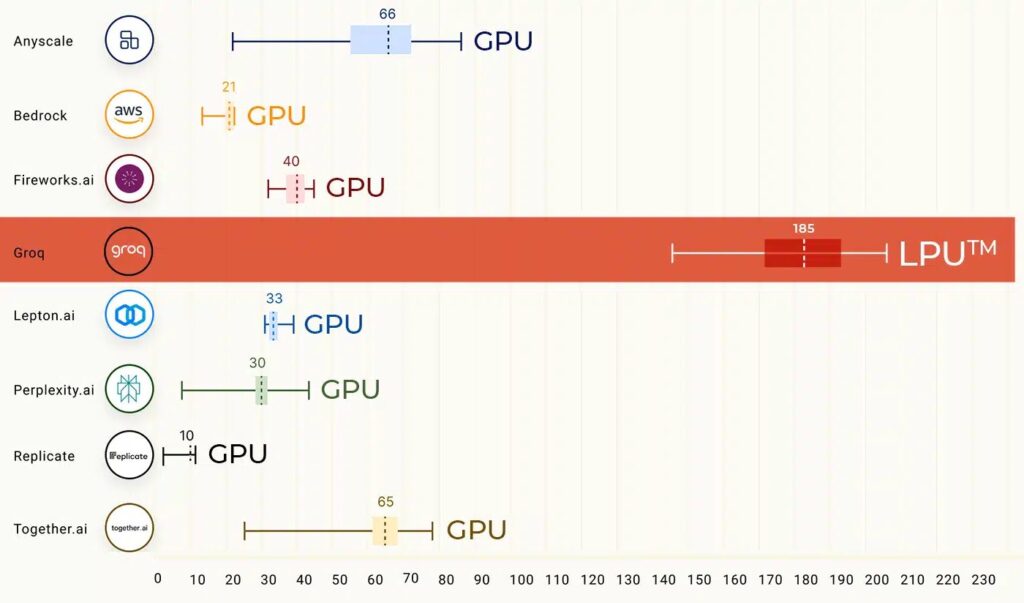
It has more compute power, faster generation speed, and higher accuracy than graphics processors (GPUs). It also has no external memory bandwidth bottlenecks and can auto-compile >50B LLMs.
The GPU Bottleneck
Enter the GPU (Graphics Processing Unit)—the workhorse of deep learning. GPUs handle parallel tasks well, making them ideal for training neural networks. However, when it comes to sequential processing, they stumble. LLMs rely heavily on sequential computations, and GPUs struggle to keep up. Imagine a marathon runner trying to sprint—it’s not their forte.
Introducing the LPU
LPU stands for Language Processing Unit, and it’s here to bridge the gap. Developed by Groq, the LPU Inference Engine is a game-changer. Let’s break down what makes it special:
- Compute Power: An LPU system packs as much or more compute than a GPU. It flexes its muscles, effortlessly handling LLMs’ hunger for calculations.
- Memory Bandwidth: LLMs crave data like a bookworm craves knowledge. The LPU ensures there are no memory bottlenecks. It fetches data instantly, keeping the LLMs well-fed.
- Sequential Performance: The LPU dances through sequential tasks. It’s like a synchronized swimmer gliding through water. Whether it’s predicting the next word or analyzing sentiment, the LPU excels.
- Single Core Architecture: Simplicity is elegance. The LPU’s single core design optimizes sequential workloads. No more juggling multiple cores—it’s laser-focused.
- Synchronous Networking: Even in large-scale deployments, the LPU maintains synchronicity. It’s the conductor of an orchestra, ensuring every note is in harmony.
- Auto-Compilation Magic: LLMs come in all shapes and sizes. The LPU auto-compiles models with over 50 billion parameters. It’s like having a personal code wizard.
- Instant Memory Access: No waiting in line. The LPU grabs data from memory like a ninja snatching a scroll. Speed matters, and the LPU delivers.
- High Accuracy, Lower Precision: Precision matters, but the LPU doesn’t break a sweat. It maintains accuracy even at lower precision levels.
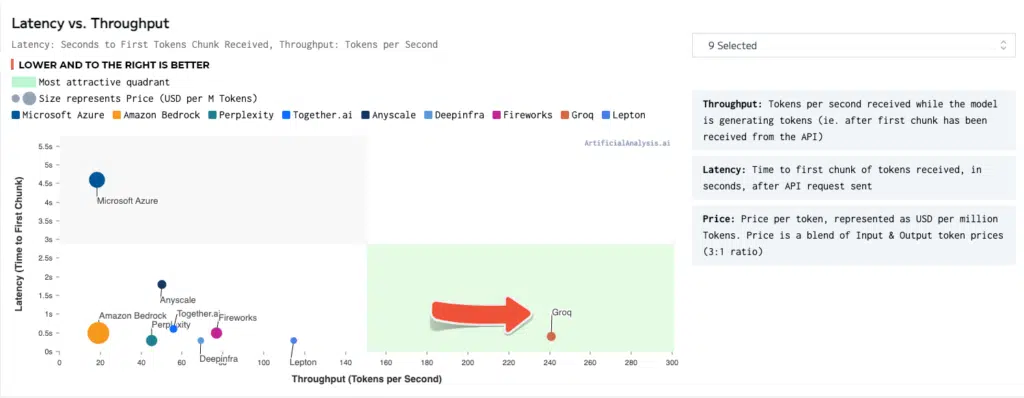
The performance of Groq on an LPU™ Inference Engine
Groq claims to have achieved over 300 tokens per second per user on Llama 2 (70B), a state-of-the-art LLM, running on an LPU system.
The vision and promise of Groq
Groq aims to provide a superior AI experience with low latency, real-time delivery, and energy efficiency. Groq also promises to make it real for customers, partners, and prompters.
Conclusion
The demand for LLMs is accelerating, and current processors are struggling to keep up. LPUs represent a significant breakthrough in the field of generative AI, offering a new type of processing system designed specifically for LLMs. With their exceptional sequential performance, single-core architecture, and high accuracy, LPUs are poised to revolutionize the way we interact with technology. The future of generative AI is bright, and LPUs are leading the charge.
Source: Groq
0 Comments